5.3 Running Code (Safely)
In order to support both responsive evaluation and simulate an arbitrarily deep stack, Pyret has an evaluation model that does not exactly match JavaScript’s.
When a Pyret function is compiled, it gets an extra try/catch handler wrapped around it that listens for special Pyret-specific exceptions. That means when it’s running, we can think of the stack frame of the function as having an extra layer around it:
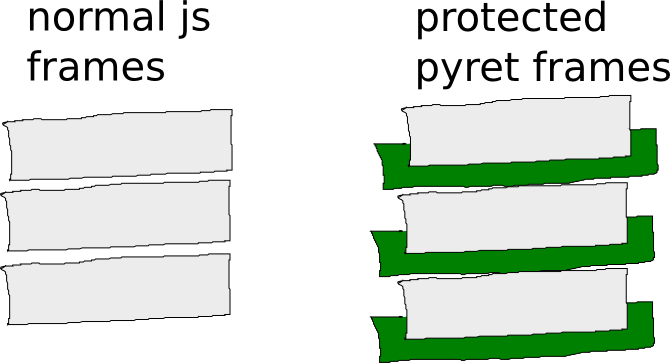
When a Pyret function detects (via a counter stored in the runtime) that the stack depth is approaching the maximum that JavaScript can tolerate, it throws an exception:

When the exception is encountered by one of the handlers, it attaches enough information to the exception to restart the handler’s frame before allowing the exception to coninue:

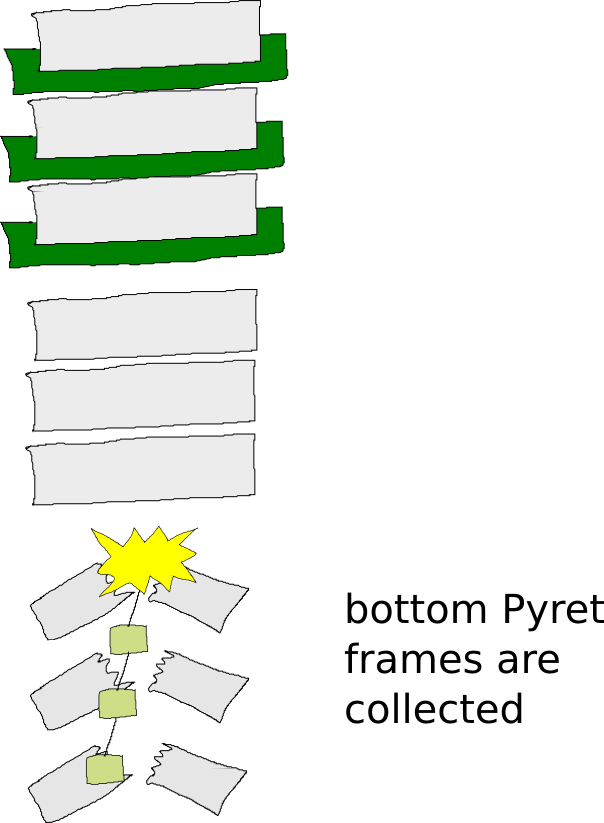
This continues through the entire stack, storing a list of Pyret stack frames stored on the exception object:
Until finally, the entire Pyret stack is reified on the exception object, and all the JavaScript frames from the Pyret functions are gone:

This exception is caught by Pyret’s toplevel, which restarts the bottommost element of the stack, which now has nothing above it, instead of a full stack. It can make progress with the available JS stack. The runtime can store the existing Pyret stack and add to it if the JS stack runs out again.
This works just fine if all that’s running is Pyret code. However, there are two cases where JavaScript code that interacts with Pyret needs to be handled delicately.
5.3.1 JS Pretending to be Pyret
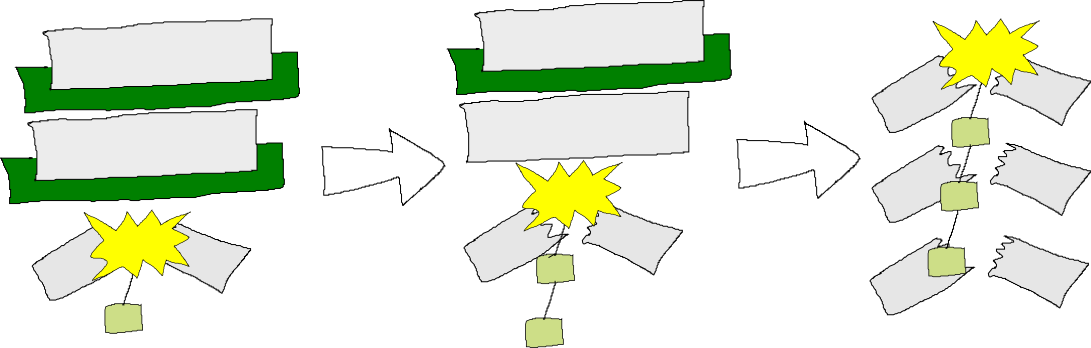
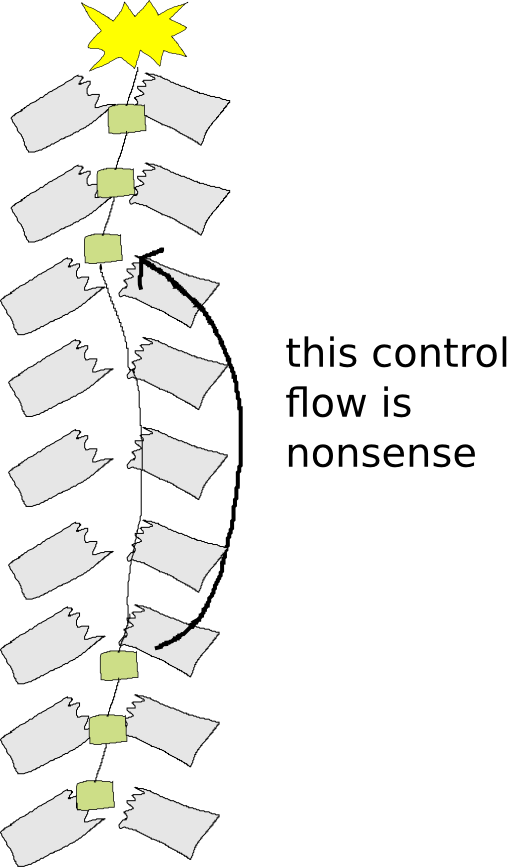
Many library use cases, like data structures and convenience functions, are written as JavaScript code that emulates Pyret function calls. However, if JS code calls back into Pyret code, care is in order. Here’s what the stack looks like if Pyret calls JavaScript that calls Pyret again:

If the stack limit is reached and an exception thrown, the bottom Pyret frames will have their intermediate state stored:
But the pure JavaScript frames have no stack management handlers installed, so they are skipped without consideration for any intermediate state they may contain.
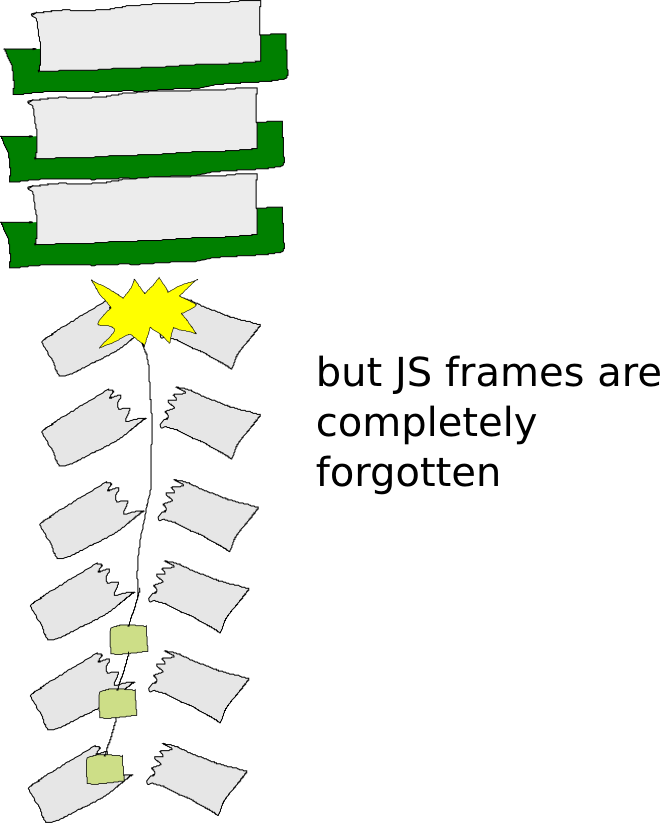
The resulting stack doesn’t accurately represent the program that was being executed. It is, quite literally, nonsense, because a Pyret function will return directly to another Pyret function, ignoring all of the intermediate JavaScript logic. Using this pattern without any guards or protection will create programs that simply produce wrong answers.
Pyret’s runtime defines a function called Runtime.safeCall that allows pure JavaScript to participate in the Pyret stack.
Runtime.safeCall combines the two provided functions in a special stack frame:
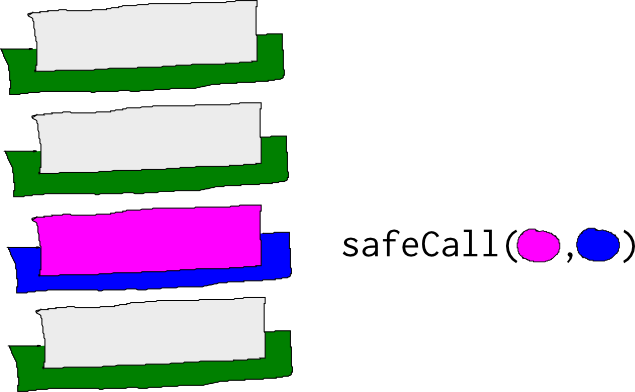
The first argument is called, and in normal execution, its return value is passed to the second function. The second function’s return value is then the return value of the whole call. However, if a stack exception occurs, the second function is registered as the frame stored on the Pyret stack:
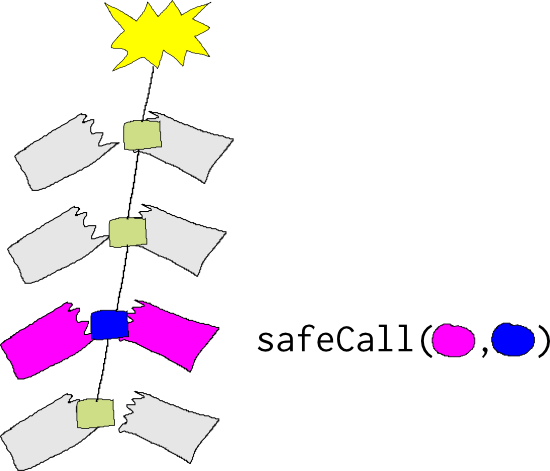
This means that in the simulated stack, the second callback (blue in the picture), will receive the result of the last call to a stack-managed function from the first callback (pink in the picture):

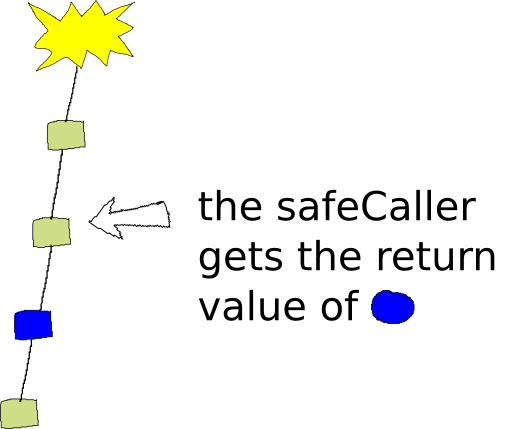
Then, when the second callback (blue) is run, it’s return value will be passed up the stack to the Pyret function that called into the use of safeCall:
The usual pattern for using Runtime.safeCall is with a single call to a Pyret function, or another function that calls a Pyret function. As long as all the calls to Pyret functions are in tail position in safeCalls, no information will be lost.
Examples
Calling torepr can consume a lot of stack (for serializing large data structures), so JavaScript-implemented torepr methods often need to use safeCall. For example, a function that does work with the result of a torepr call needs to use safeCall to capture the result correctly:
function makeDataType(val) { |
function torepr(self, toreprRecursive) { |
return runtime.safeCall(function() { |
return toreprRecursive.app(val); |
}, function(valAsString) { |
return "Value was: " + valAsString |
}) |
} |
return runtime.makeObject({ |
_torepr: runtime.makeMethod1(torepr) |
}); |
} |
We haven’t found a way to turn this into an error, so testing and code review are the only real protections. The best way to test for this kind of problem is to pass deeply recursive callbacks into the JS library, which can trigger odd behavior. If you have suggestions for patterns or tools to make this less error-prone, let us know. If instead it was written as:
function makeDataType(val) { |
function torepr(self, toreprRecursive) { |
var valAsString = toreprRecursive.app(val); |
return "Value was: " + valAsString; |
} |
return runtime.makeObject({ |
_torepr: runtime.makeMethod1(torepr) |
}); |
} |
then, a torepr call on the resulting object could use up all the stack while evaluating toreprRecursive.app(val), causing the string concatenation in the return to simply be ignored.
5.3.2 Asynchronous JS and Pyret
Lots of JavaScript code works asynchronously, with callbacks that are registered to be invoked after the stack clears. The control flow of these callbacks interacts with Pyret’s stack infrastructure. Most callback-using JavaScript code simply returns undefined immediately, and all further computation happens in either success or failure continuations. This doesn’t play nicely with Pyret’s stack-based control flow, because Pyret functions expect a meaningful return value.We could require that all Pyret code that uses JS callback libraries use Pyret callbacks, but it’s hardly elegant to require that all students learn to use callbacks before they can import an image.

In order to weave the control flow of Pyret through the success and failure continuations of callbacks, the runtime provides a way to pause and reify the Pyret stack for later resumption.
When pauseStack is called, a special pause exception is thrown, that stores the callback passed in as the argument to pauseStack. The pause exception collects Pyret stack frames in the same way as a stack exception, it just keeps track of the callback as well:
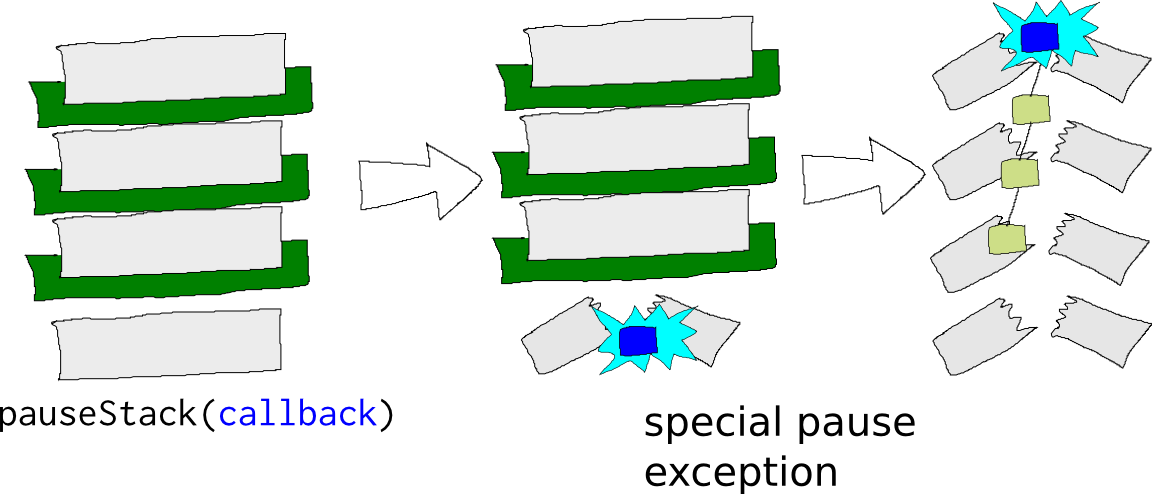
The pause exception is handled specially at the toplevel, by creating a Restarter object that is capable of resuming, stopping, or signalling an error at the point the Pyret stack was paused. This Restarter is passed into the callback argument to pauseStack, which can then asynchronously restart the Pyret process:
Restarter :: { |
resume: PyretVal → Undefined, |
error: (PyretError U PyretVal) → Undefined, |
break: → Undefined |
} |
Example:
myRuntime.pauseStack(function(restarter) { |
var request = $.ajax("/api"); |
request.then(function(answer) { |
restarter.resume(toPyretResponse(answer)); |
}); |
request.fail(function(err) { |
restarter.error(myRuntime.ffi.makeMessageException("Request failed")); |
}); |
}); |
Some things to note:
It is an error to call more than one of resume/error/break: a Restarter is not a continuation that can be invoked multiple times.
If none of the callbacks are ever called, from the point of view of the running Pyret process, the program is in an infinite loop (for example, the IDE may show a "running" GIF forever). This includes the case where executing the callback ends in an error. So, using pauseStack requires some care in writing robust JavaScript code, or odd behavior can result.
Similar to Runtime.pauseStack, but used from outside the runtime (e.g. in the REPL), to schedule a pause. Since the point of interruption (and resumption) is not predictable from outside the Pyret thread, the resume method of the Restarter for schedulePause ignores any value passed to it; it always resumes the computation exactly as it would have continued had it not been paused.
If Runtime.schedulePause is called during a synchronous Runtime.run, the runtime will still wait until the next stack exception to call the given Restarter. If called during an asynchronous run, the next time a setTimeout is triggered, the Restarter will be called.
If Runtime.schedulePause is called multiple times before Pyret checks for scheduled pauses, the last call’s Restarter is used, and any earlier calls are ignored.
5.3.3 Starting a New Pyret Stack
The description of Runtime.safeCall and Runtime.pauseStack assume that the calls are being made in a running Pyret execution context. This is the case for most library code that would get run via import, and be using external APIs.
However, some applications may need to start new Pyret instances from scratch. In order for the special PauseExceptions and StackExceptions to be caught at the top level and correctly restarted, the handlers need to be correctly installed. This is done by Runtime.run:
The first argument is the program to run, which takes a Runtime (which is always the same as the runtime run is called on), and a Namespace as arguments. Pyret programs are compiled to look for any global identifiers in Namespace. The second argument is the Namespace passed to the function to run (adding to the namespace is useful for e.g. putting REPL-defined identifiers into scope). RunOptions has only one field: sync, which is a boolean indicating if the program should be run synchronously or not. This is described more in Synchronous vs. Asynchronous Execution. Finally, the last argument is a callback that gets either a Success or Failure result, described in Result Data Structures.
Only one run call can be active for a given runtime at once. If it is called more than once, an error that says "run called while already running" will be raised. New calls to Runtime.run should only be used at the logical start of a Pyret program’s execution (e.g. running the definitions window, running a REPL entry, running a standalone test case start-to-finish), not for loading libraries, interacting with native JS APIs, or managing asynchronous APIs.
5.3.3.1 Synchronous vs. Asynchronous Execution
The sync flag passed to Runtime.run changes how stack pauses are managed. In synchronous mode (sync: true), when a stack or pause exception reaches the top level, it is immediately restarted. This is the fastest option, and is the default for Pyret running from the command-line.
However, when executing synchronously, Pyret never yields to the event loop. If sync: true were used in a context with user interaction, like a browser page, the UI thread would never get a chance to run. If sync is set to false, when the stack limit is reached, or a pause execption is thrown, it is restarted after first yielding to the event loop (using setTimeout). This provides a window for the browser to process click and key events, avoiding page lockup. This also gives the ability for UI elements to trigger calls to Runtime.schedulePause, which will call back to the pauser the next time the Pyret thread restarts.
5.3.3.2 Result Data Structures
Represents a successful completion of a Pyret execution with Runtime.run.
Checks if a value is a SuccessResult.
The field that stores the answer of a SuccessResult.
Represents a Pyret execution with Runtime.run that ended in some kind of exception (either from Pyret or an internal JavaScript error).
Checks if a value is a FailureResult.
The field that stores the exception value of a FailureResult.